The structure of my upcoming AI project's tech stack
Next.js, Supabase and Hugging Face Transformers.js

This article belongs to the series - Supabase One for All
Introduction
In the world of modern web development, the choice of tools and libraries can make or break your application. It's not just about the aesthetics or the speed, but the ease of development, scalability, and integration capabilities that truly distinguish an application. In this article, we'll combine some of my favorite tools for web development: Next.js+TailwindCSS, Supabase, and the new kid in town, Hugging Face Transformers.js library.
Let's do a quick overview:
Next.js, developed by Vercel, is a React-based framework that provides out-of-the-box solutions for rendering on the server side, static site generation, and more. It accelerates the development process, ensuring your application is fast and SEO-friendly from the get-go.
Supabase is an open-source Firebase alternative that provides you with a database, authentication, real-time subscriptions, and an easy integration with Hugging Face. It empowers developers to build applications with less boilerplate code and more focus on business logic. They introduced Supabase Edge Functions last year, allowing developers to run serverless functions at the edge, closer to the users which reduced latency and enhanced performance and became particularly beneficial these days for AI computations that, in the past, may have necessitated round trips to central servers.
Lastly, Hugging Face Transformers.js brings the power of machine-learning models directly to the browser. With the vast array of pre-trained models available, developers can easily embed advanced text processing capabilities into their applications.
A Brief Case Study: Consider TextAnalyzerPro, a hypothetical web application that allows users to input large blocks of text. The application then utilizes machine learning models to analyze the text's sentiment, extract key entities, and summarize its content. Built using Next.js, it boasts a sleek interface crafted with TailwindCSS. The backend is powered by Supabase, handling user data profiles, authentication, storing data in a vector database and ensuring real-time feedback. The core text processing is done using a pre-trained model from Hugging Face Transformers.js, executed directly in the browser for faster results 😎

By the end of this article, you'll have a clear pathway on how to integrate all these technologies into a single, coherent, and powerful web application, much like TextAnalyzerPro.
Setting up the development environment
Before we start coding, we need to set up our development environment. This involves creating a Next.js app, installing dependencies, configuring Supabase, and integrating everything.
Create-next-app
First, we'll create a new Next.js project using create-next-app. This gives us a basic scaffolded app we can build on top of.
Run the following in an empty directory to generate a new project called TextAnalyzerPro:
npx create-next-app@latest
What is your project named? TextAnalyzerPro
Would you like to use TypeScript? No / Yes
Would you like to use ESLint? No / Yes
Would you like to use Tailwind CSS? No / Yes
Would you like to use `src/` directory? No / Yes
Would you like to use App Router? (recommended) No / Yes
Would you like to customize the default import alias (@/*)? No / Yes
What import alias would you like configured? @/*
By following the CLI instructions, you should be able to create a new Next.js boilerplate with a basic configuration. For a detailed walkthrough, refer to the official Next.js documentation.
Next, we'll install the required libraries our app depends on:
npm install tailwindcss postcss autoprefixer @supabase/supabase-js @xenova/transformers
This adds:
Autoprefixer - for handling vendor prefixes
Tailwind CSS - for styling purposes
PostCSS - for processing CSS
SupabaseJS - for accesing the Supabase's API
Transformers - for running pre-trained models
I designed this example in under an hour, just to demonstrate how quickly you can get on track:
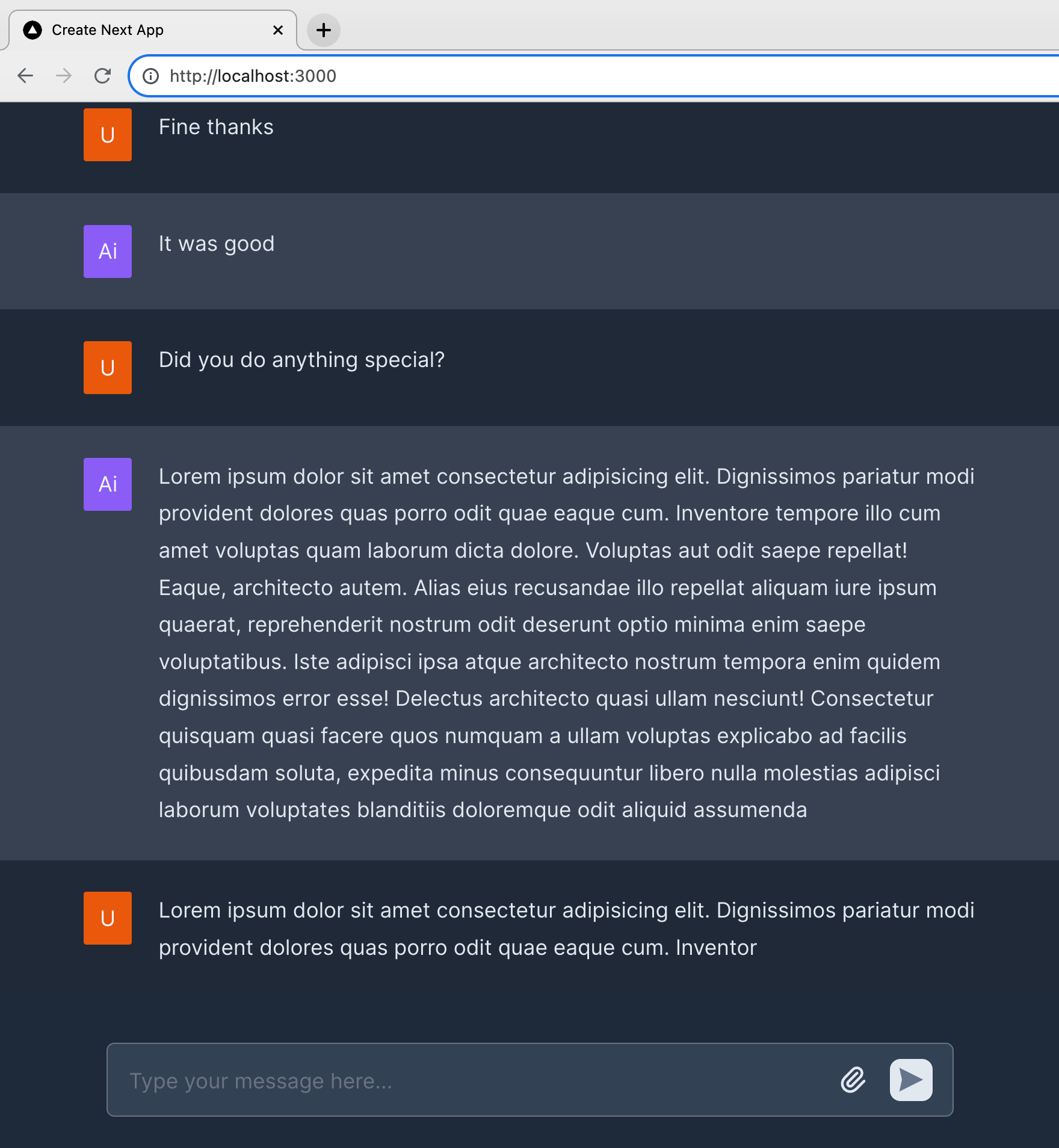
Here is a quick example of the message component:
Configuring Supabase
Before you can harness the features of Supabase, you need an account. Register at Supabase.io
If you haven't used Supabase yet or are just greeting the tech, check this introductory article!
After logging in, click on the New Project button, fill in the necessary details for your project. Once created, you will be provided with a URL and API key. Make a note of these; they will be crucial for connecting your Next.js application to Supabase.
Remember to check Supabase's official guide for an in-depth setup.
brew install supabase/tap/supabase. However, it can be installed on any popular platform.Generate embeddings with Supabase Edge Functions
Supabase has also hosted on Hugging Face, a small General Text Embeddings (GTE) model with power-ups ONNX weights, making it compatible with the Transformers.js library as we mentioned before.
Developing and debugging Edge Functions requires setting up a local development environment, check out this guide on how to do so!
🤔 But, wait a second, what the heck are embeddings?
Embeddings are vector representations of text generated by machine learning models like BERT. Each word or piece of text gets converted into a vector of continuous numbers based on the model's understanding.
For example, the word "apple" may become:
[0.4, 0.2, -0.1, 0.7, ...]
These numerical vectors capture semantic meaning and relationships between words. Words with similar meanings will have similar embeddings.
Some key advantages of embeddings:
Represent concepts mathematically so they can be easily processed by ML algorithms
Capture semantic similarities between words based on context
Low-dimensional representation of text that can be searched and clustered
Efficient way to represent and compare large volumes of text data
etc
This model also benefits from fewer dimensions (384), it is 4 times smaller compared to popular models like OpenAI's text-embedding-ada-002 and even ranks higher on the MTEB leaderboard. There is a detailed article explaining why fewer dimensions are better on their blog that I recommend consulting.
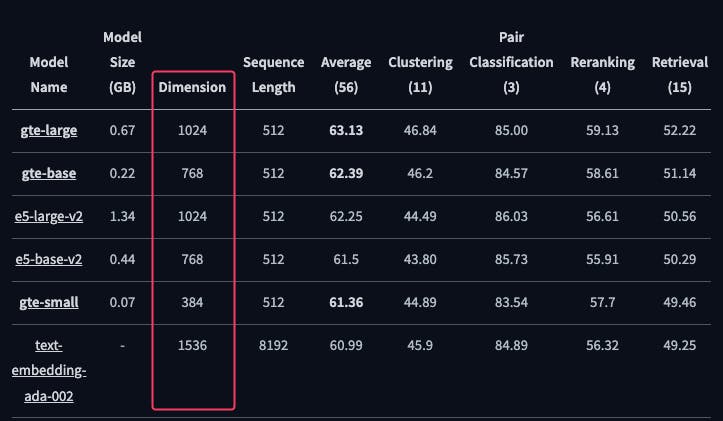
which directly translates into:
Fewer calculations for each computed distance
Reduced-cost usage
With that in mind, let's generate our embeddings by invoking the GTE model within an EDGE Function.
If you don't know how to create an EDGE Function in Supabase, I have a step-by-step article about how to do so, check it out!
This is the function I created to generate the embeddings and insert them into a vector database.
Let's do a quick review:
First, we import the required libraries that were configured in the
import_map.jsonfile.Then, we retrieve the environment keys
SUPABASE_URLandSUPABASE_ANON_KEYdirectly from the Deno environment, as these are variables exposed by the EDGE ecosystem.We load the GTE model
Supabase/gte-smallhosted by Supabase into the pipeline.Then pass the input to the pipeline to generate the embeddings and extract them from the output data
Finally, insert the generated embeddings into the vector database
To remove the ban just go to Project Settings ➡️ Database ➡️ Banned IPs. Search for yours and click on the right-side button that says unban IP.
How to create a vector database in Supabase?
To achieve this we are gonna create a migration with the following command in our project:
## I have called initial_schema, but you can call it as you want
supabase migrations new initial_schema
this command is gonna generate an empty .sql file, you can create something similar to:
create extension vector with schema extensions;
CREATE TABLE collections (
id SERIAL PRIMARY KEY,
embedding vector(384)
);
create index on collections using hnsw (embedding vector_cosine_ops);
Supabase vector experienced a significant performance improvement, as announced on the 6th of September, with the addition of pgvector v0.5.0 and the HNSW (Hierarchical Navigable Small World) index. More information can be found on their blog. And that's what we are using here:
First, we enable the vector extension.
Afterward, we can create a table that includes a column of the vector type.
Finally, we create an index utilizing the HNSW index 😅
vector(384) displayed in the embedding column represents the dimensional quantities associated with the GTE model we previously discussed. Remember, fewer dimensions are better.Now, when you call the function, your table should populate with something like this:

Use cases
Up to this point, numerous potential use cases can be followed:
Semantic search - Store embeddings for documents/pages. Then search by converting the query to embedding and finding the closest matches.
Content recommendations - Embed user history and products. Recommend items with similar embeddings.
Sentiment analysis - Pass text through the sentiment classifier model to embed "positive" or "negative" sentiment.
Chatbots - Embed user input and bot responses to select the most appropriate reply.
Summarization - Generate embeddings for sentences in articles. Select sentences with embeddings closest to the overall article embedding as a summary.
Clustering - Embed documents/users then cluster using K-means or hierarchical clustering to find groups.
Information retrieval - Embed query and candidate passages. Return to most similar passages.
Text generation - Embed initial text, and pass it to the generator model to get autocompletion matching the embedding.
Spam detection - Classify texts as spam/not spam. Embed samples to train the classifier model.
Language detection - Embed text samples from different languages. Build a model to classify language based on embedding proximity.
Examples
Let's take the TextAnalyzerPro example from the beginning:
Imagine users submitting the following text data related to their customer support experience:
Text A: "I loved the latest version of the software. It has become more user-friendly and intuitive."
Text B: "The customer support was very unhelpful and dismissive. I'm thinking of switching to another service."
Processing the Data:
Generating Embeddings:
When these texts are submitted to
TextAnalyzerPro, Supabase Edge Functions, with the help of the GTE Small model, convert them into embeddings. These embeddings capture the semantic essence of each text as can be described in the next scenarios:Sentiment Analysis:
Using a pre-trained model like BERT or RoBERTa, the embeddings are analyzed for sentiment:
Text A: Positive
Text B: Negative
Entity Extraction:
Identifying key entities or themes in each text:
Text A: Entities extracted: ["latest version", "software", "user-friendly", "intuitive"]
Text B: Entities extracted: ["customer support", "unhelpful", "dismissive", "another service"]
Summarization:
Generating concise summaries of the submitted texts:
Text A: "The user praises the software's latest version for its enhanced user-friendliness."
Text B: "The user is unhappy with the customer support and is considering switching services."
Final thoughts
That covers the basis of how to build a modern web application from start to finish with Next.js, Supabase and Hugging Face technologies! They provide the essentials for great performance, user experience, infrastructure and AI capabilities.
By combining reusable components, intelligent APIs and global CDN hosting, we can develop full-stack apps faster than ever.
The entire stack is free and open source, enabling rapid prototyping and iteration.
There's lots of room for additional features like real-time subscriptions, analytics, and more built on this stack - so stay tuned for upcoming articles!
Potential improvements and extensions
Here are some ideas for enhancing the application even further:
Implement real-time functionality with Supabase subscriptions for instant updates.
Add a voting or commenting system for users to interact with posts.
Analyze text with Hugging Face's sentiment analysis to detect tone.
Create user profiles and avatars for more personalization.
Add search and filtering so users can easily find posts.
Build a recommendation system to suggest content to users.
Implement analytics to track page views, interactions, and conversions.
Support editing and deleting posts to keep content up-to-date.
Add rich media embedding for videos, images, and other media.
Build a mobile app version using React Native to complement the web.
Encouraging further exploration and learning
This article provided an overview of building an app with these technologies, but there's always more to learn. Here are some resources for leveling up your skills:
Next.js Docs - https://nextjs.org/docs
Supabase Docs - https://supabase.com/docs
Hugging Face Docs - Transformers.js
Next.js Learn Course - https://nextjs.org/learn
Supabase YouTube - https://www.youtube.com/channel/UCJ9jj5YMzo-HsyM6WG9Q_Lg
Start building! Applying these frameworks to your projects is the best way to reinforce what you've learned. And don't hesitate to dive into the documentation or communities when you need help.
Happy coding!